메모리 계층
정의 및 특징

- CPU는 그저 메모리에 올라와 있는 프로그램의 명령어들을 실행할 뿐임
- 메모리 계층이란 메모리를 필요에 따라 여러 종류로 나눈 것
- 각 레벨은 하위 레벨의 캐시로서 동작함
메모리 종류
| 메모리 |
정의 |
휘발성 |
속도 |
기억 용량 |
| 레지스터 |
CPU 안에 있는 작은 메모리 |
휘발성 |
가장 빠름 |
가장 적음 |
| 캐시 |
L1, L2 캐시를 지칭 |
휘발성 |
빠름 |
적음 |
| 주기억장치 |
RAM을 가리킴 |
휘발성 |
보통 |
보통 |
| 보조기억장치 |
HDD, SSD를 일컬음 |
비휘발성 |
느림 |
많음 |
- 램은 하드디스크로부터 일정량의 데이터를 복사해서 임시 저장하고 이를 필요 시마다 cpu에 빠르게 전달하는 역할을 함
- 계층 위로 올라갈수록 가격은 비싸지는데 용량은 작아지고 속도는 빨라짐
캐시 메모리
등장 배경

- 컴퓨터가 발전해감에 따라 프로세서의 발전 속도를 메인 메모리가 따라가지 못함
- 프로세스가 아무리 빨라도 계산에 필요한 데이터를 얻기 위해서는 메인 메모리에 접근해야 했기 때문에 전체적인 시스템 성능 향상에 한계가 생김
- 따라서 CPU와 메인 메모리 사이에 캐시를 두게 됨
정의 및 특징

- 빠른 장치와 느린 장치에서 속도 차이에 따른 병목 현상을 줄이기 위한 임시 메모리임
- 데이터를 접근하는 시간이 오래 걸리는 경우를 해결하고 반복된 연산의 시간을 절약할 수 있음
- 이렇게 속도 차이를 해결하기 위해 두 계층 사이에 있는 계층을 캐싱 계층이라고 함
- 캐시 메모리와 주기억장치 사이에서 정보를 옮기는 것을 사상(Mapping)이라고 함
캐시의 종류
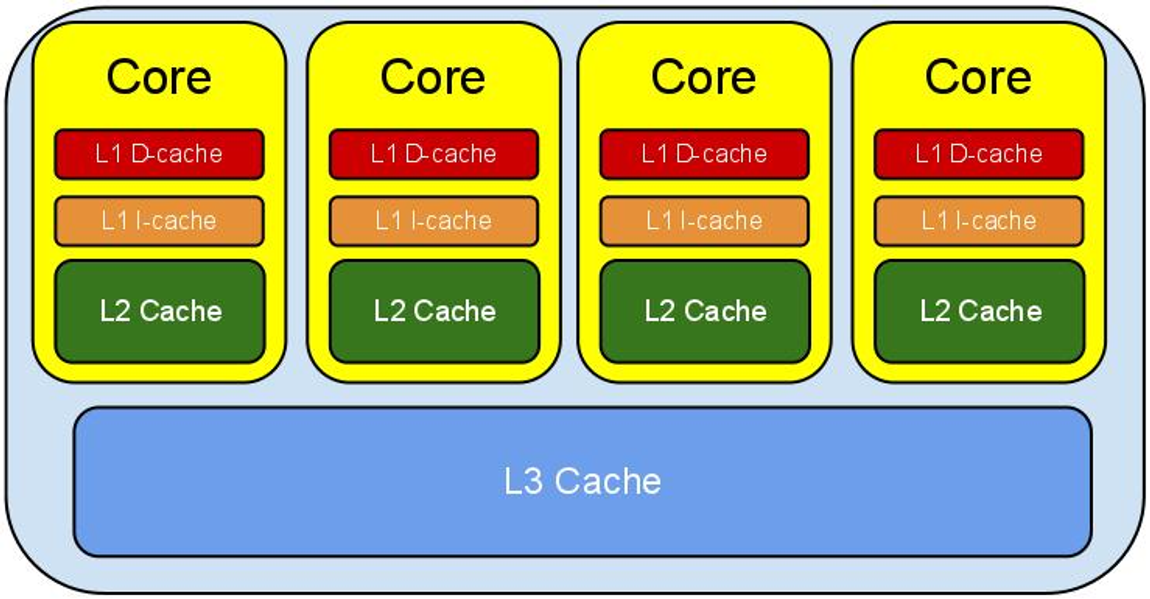
- L1 캐시: 일반적으로 CPU 칩 안에 내장되어 데이터 사용/참조에 가장 먼저 사용됨
- L2 캐시: L1보다 느리나 용량이 더 큼
- L3 캐시: 멀티 코어 시스템에서 코어가 공유하는 캐시
캐시의 전송 단위
 https://ssoonidev.tistory.com/35
https://ssoonidev.tistory.com/35
- 워드(word)
- CPU의 기본 처리 단위로, 블록/라인을 구성하는 기본 단위임
- 블록(block)
- 메모리를 기준으로 잡은 캐시와의 전송 단위
- 캐시 라인과 크기가 같으며, 메모리 블록은 여러 개의 워드로 구성되어 있음
- 캐시라인
- 캐시에 데이터를 저장할 때 특정 자료구조를 사용해 묶음으로 저장하는 것
- 캐시에 저장하는 데이터에는 메모리 주소 등을 기록해준 태그를 달아놓을 필요가 있으며, 이러한 태그들의 묶음을 캐싱 라인이라고 함
- 캐시는 여러 개의 캐시 라인으로 이어져 있으며, 메모리로부터 가져올 때도 캐싱 라인을 가져옴
지역성의 원리
- 캐시가 효율적으로 동작하기 위해서는 캐시의 적중율(Hit-rate)를 극대화해야 함
- 어떤 데이터가 자주 사용되는가에 대한 근거로 사용되는 것이 바로 “지역성”
- 시간 지역성(temporal locality)
- 특정 데이터가 한번 접근되었을 경우, 가까운 미래에 또 접근할 가능성이 높은 것
- 예를 들어 for 반복문에서는 계속해서 변수 i에 접근이 이뤄짐
- 공간 지역성(spatial locality)
- 최근 접근한 데이터를 이루고 있는 공간이나 그 가까운 공간에 접근하는 특성을 말함
- 예를 들어 하나의 일차원 배열에 연속적으로 접근하는 경우가 있음
캐시히트와 캐시미스

- 캐시 히트의 경우: 캐시에서 원하는 데이터를 찾음
- 캐시 미스 & 메모리에서 찾았을 경우: 메모리 → 캐시 메모리 → CPU 레지스터에 복사
- 캐시 미스 & 메모리에서 찾지 못했을 경우: 보조기억장치 → 메모리 → 캐시 메모리 → CPU 레지스터에 복사
- 캐시히트의 경우 위치도 가깝고 CPU 내부 버스를 기반으로 작동하기 때문에 속도가 빠름
- 반면 캐시미스는 메모리에서 가져오며, 시스템 버스를 기반으로 작동하기 때문에 느림
캐시 매핑
캐시 매핑의 필요성
- 캐시에 데이터를 저장했어도 그 위치를 모른다면 시간이 오래 걸리게 됨
- 캐시매핑이란 주기억장치에서 메모리로 데이터를 전송하는 방법으로 3가지가 존재함
- 레지스터는 주 메모리에 비하면 굉장히 작고 주 메모리는 굉장히 크게 때문에 작은 레지스터가 캐시 계층으로써 역할을 잘 해주려면 이 매핑을 어떻게 하느냐가 중요함
직접 매핑(directed mapping)

- 데이터가 캐시에 들어올 때 이미 자리가 정해져있는 방식으로, 블록 단위로 저장됨
- 메모리가 1~100이 있고 캐시가 1~10이 있다면 1:1~10, 2:1~20… 이런 식으로 매핑하는 것
- 처리가 빠르지만 캐시를 자주 교체해야 해서 적중률이 낮음
- 메모리 주소 구성
- 태그: 메인 메모리의 몇번째 블록인지를 알려줌
- 라인: 같은 위치에 저장되는 00000과 00100을 구분하기 위함
- 워드: 블록의 크기를 나타냄(00000, 00001)
연관 매핑(associative mapping)

- 직접 매핑의 단점을 보완하기 위해 등장
- 메인 메모리의 순서와 아무런 관련 없이 저장됨
- 모든 블록을 탐색해야 해서 속도가 느리지만 적중률이 높음
- 혹은, 병렬 검사를 위해 복잡한 회로가 필요함
집합 연관 매핑(set associative mapping)

- 직접 매핑과 연관 매핑을 합쳐놓은 것
- 메모리는 1~100, 캐시는 1~10이 있다면 캐시 1~5에는 1~50의 데이터를 무작위로 저장시키는 것을 말함
- 세트 번호로 영역을 탐색하여 연관 매핑의 병렬 탐색을 줄임
- 모든 라인에 연관 매핑처럼 무작위로 위치하여 직접매핑의 단점도 보완함
캐시 쓰기 정책
 https://velog.io/@khsfun0312/캐시-정책알고리즘
https://velog.io/@khsfun0312/캐시-정책알고리즘
캐시의 활용
웹 브라우저의 캐시
- 보통 사용자의 커스텀한 정보나 인증 모듈 관련 사항들을 웹 브라우저에 저장해 추후 서버에 요청할 때 자신을 나타내는 아이덴티티나 중복 요청 방지를 위해 쓰임
- 쿠키
- 4KB까지 데이터를 저장할 수 있는 key-value 저장소
- 클라이언트 또는 서버에서 만료기한 등을 정할 수 있는데, 보통 서버에서 설정함
- 로컬 스토리지
- 만료기한이 없는 key-value 저장소로, 클라이언트에서만 수정 가능
- 10MB까지 저장할 수 있으며 웹 브라우저를 닫아도 유지됨
- 세션 스토리지
- 만료기한이 없는 key-value 저장소로, 클라이언트에서만 수정 가능
- 탭 단위로 세션 스토리지를 생성하며, 탭을 닫을 때 데이터도 삭제됨
- 5MB까지 저장 가능함
데이터베이스의 캐싱 계층

- 데이터베이스 시스템을 구축할 때도 메인 데이터베이스 위에 redis DB 계층을 ‘캐싱 계층’으로 두어 성능을 향상시키기도 함
References