SQL 성능 개선을 위해 가장 많이 활용되는 방법이 인덱스 활용이다. 하지만 단순히 인덱스만 적용한다고 해서 무조건 해결되는 게 아니다. 인덱스를 적절하게 활용해야만 DB 성능이 개선된다.
인덱스란?
개념
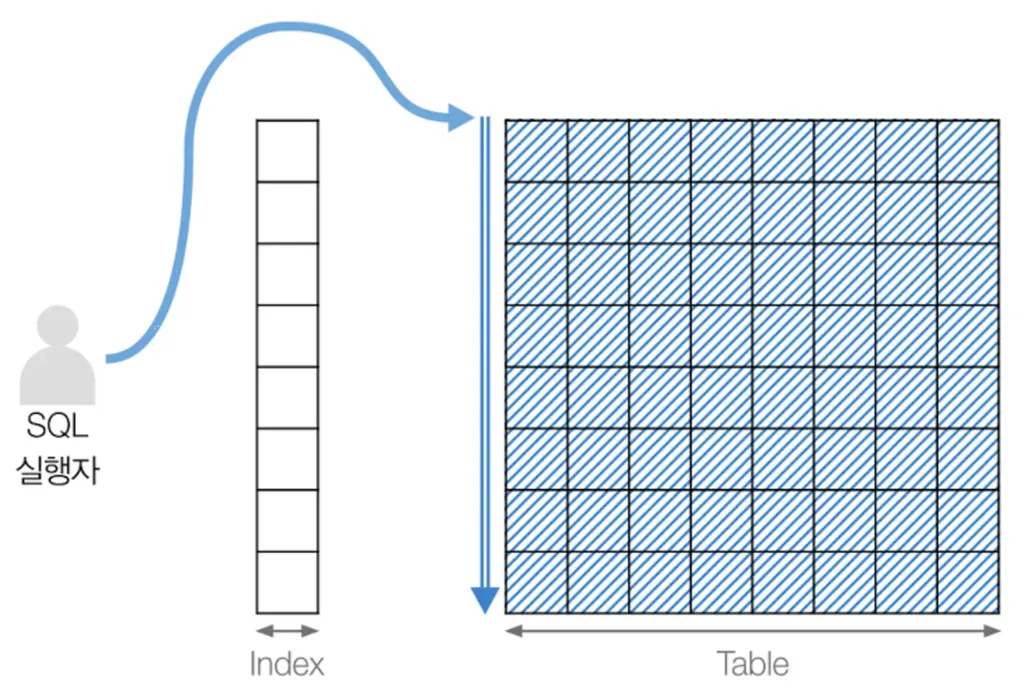
추가적인 쓰기 작업과 저장 공간을 활용하여 DB 테이블에 대한 검색 성능의 속도를 높여주는 자료 구조
데이터를 빨리 찾기 위해 특정 칼럼을 기준으로 미리 ‘정렬’해둔 표
인덱스를 활용하면 UPDATE/DELETE 성능도 함께 향상됨. 해당 연산 수행을 위해서는 조회가 먼저 필요하기 때문
예시
users 테이블에 1만 개의 row가 있을 때, 23살인 사용자를 조회한다고 해보자. 인덱스가 없다면 만 개의 데이터를 전부 찾아봐야 할 것이다. 이를 Full Scan이라고 한다. 그런데 만약 사전에 나이를 기준으로 데이터를 정렬해둔다면 어떨까? (1)이미 정렬되어 있기 때문에 23살 데이터의 위치를 찾기도 빠르고, (2)24살 이후의 데이터는 볼 필요가 없으므로 모든 데이터를 스캔할 필요가 없다.
인덱스 관리
인덱스는 항상 최신의 정렬된 상태를 유지해야 한다. 이에 따라 INSERT/UPDATE/DELETE 연산 수행 시 다음과 같은 연산이 추가적으로 진행되어 오버헤드가 발생할 수 있다.
INSERT: 새로운 데이터에 대한 인덱스 추가
DELETE: 삭제하는 데이터의 인덱스를 ‘사용하지 않음’ 처리
UPDATE: 기존 인덱스를 ‘사용하지 않음’ 처리 후, 갱신된 데이터에 대한 인덱스를 추가
장단점
장점: 조회 성능 향상
단점: 쓰기 작업(데이터 삽입, 수정, 삭제) 성능 저하
⇒ 느려지는 이유? 인덱스를 생성한다는 것은 결국 인덱스용 테이블을 추가적으로 생성한다는 뜻이고, 인덱스 관리를 위해서는 DB의 약 10%에 해당하는 저장 공간이 필요하다고 한다. 쓰기 작업 시 원본 테이블 뿐 아니라 인덱스 테이블에도 그 값을 반영해야 한다. 즉 두 개 이상의 테이블에서 처리가 필요하기 때문에 더 느려질 수밖에 없다. 따라서 무분별한 인덱스 사용은 지양해야 한다.
인덱스 적용 케이스
INSERT, UPDATE, DELETE가 자주 발생하지 않는 칼럼
JOIN, WHERE, ORDER BY에 자주 사용되는 칼럼
데이터의 중복도가 낮은 칼럼
인덱스의 종류
기본키(Primary Key)
PK도 인덱스의 일종이기 때문에, 테이블의 데이터가 이 PK를 기준으로 정렬되어 보관됨
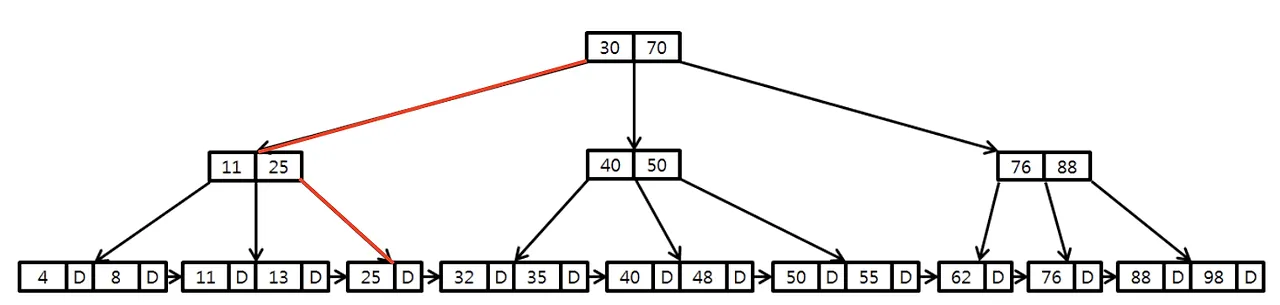
인덱스란 데이터를 빨리 찾기 위해 특정 칼럼을 기준으로 미리 ‘정렬’해둔 표라고 했는데, 그 칼럼이 PK일 경우에는 클러스터링 인덱스라고 부름
클러스터링 인덱스란 “원본 데이터” 자체가 정렬되는 인덱스를 의미함
클러스터링 인덱스에는 PK밖에 없기 때문에, PK = 클러스터링 인덱스 라고 봐도 무방
유니크(UNIQUE) 조건
MySQL은 UNIQUE 제약 조건 설정 시 자동으로 인덱스가 생성됨
그 이유는 MySQL에서 유니크 조건을 구성하고 사용할 때 기본적으로 인덱스의 원리를 활용하기 때문
즉, 유니크 옵션을 사용한다 = 인덱스를 사용한다 = 조회 성능이 향상된다
유니크 특징으로 인해 생성되는 인덱스를 “고유 인덱스(Unique Index)”라고 부름
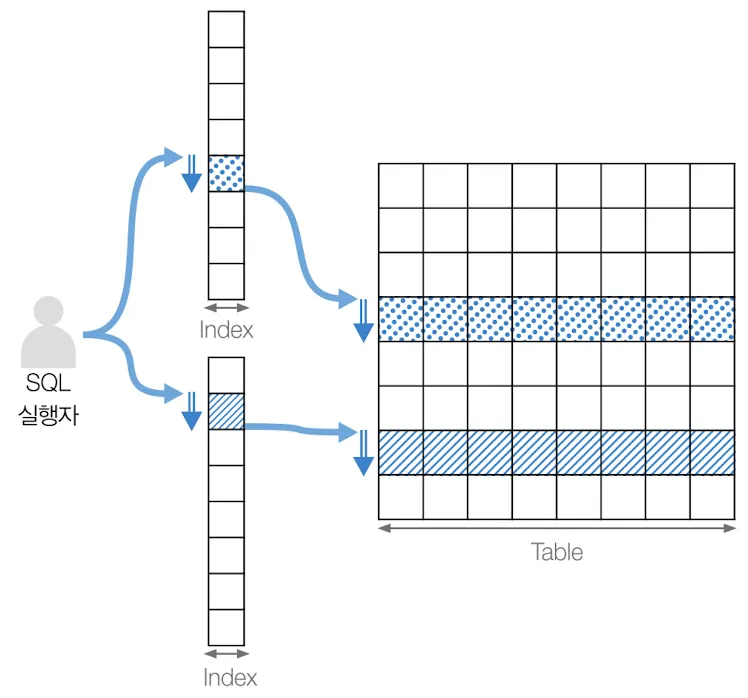
멀티 칼럼 인덱스(Multiple Column Index)
2개 이상의 칼럼을 묶어서 하나의 인덱스로 설정하는 것
즉 2개 이상의 칼럼에 대해서 미리 정렬해둔 표를 생성하는 것
여러 칼럼을 인덱스로 생성할 때에는 칼럼의 순서도 중요함. 그게 곧 정렬의 우선순위이기 때문
(부서, 나이)로 인덱스를 생성했다면, 부서를 기준으로 먼저 정렬되고 동일 부서 내 데이터들 사이에서 나이를 기준으로 다시 정렬됨
커버링 인덱스(Covering Index)
SQL문을 실행시킬 때 필요한 모든 컬럼을 갖고 있는 인덱스
SELECT id, created_at FROM users는 created_at 칼럼이 인덱스에 없기 때문에 결국 원본 테이블에 접근해야 하지만, SELECT id, name FROM users는 인덱스에 사용자가 요청하는 모든 데이터가 담겨있기 때문에 원본 테이블에 접근할 필요가 없다.
인덱스 사용 시 주의점
적절한 활용 필요
앞서 말했듯, 인덱스를 많이 정의한다고 무조건 좋은 것은 아니다. 향상되는 것은 조회 시의 성능일 뿐, 그 외의 쓰기 작업에서는 데이터의 수가 많아질수록 부하가 심해지므로, 인덱스 선언은 꼭 필요한 경우에만 사용해야 한다.
멀티 칼럼 인덱스 구성 순서
처음에 배치된 칼럼만 멀티 칼럼 인덱스에서 일반 인덱스처럼 활용 가능하다.
칼럼 순서는 소분류 > 중분류 > 대분류 순으로 구성하는 것이 좋다.
정의한 칼럼의 순서에 따라서 성능 차이가 난다. 만약 (부서, 이름) 순으로 인덱스를 정의했다면, ‘인사팀’에 해당하는 데이터를 찾은 후 ‘홍길동’을 찾을 것이다. 하지만 부서는 데이터 중복도가 높기 때문에 비효율적이며, (이름, 부서)순으로 정의하는 것이 더 높은 성능을 보일 수 있다. 즉 데이터 중복도가 낮은(≒ 카디널리티가 높은) 컬럼이 앞쪽으로 오는 게 좋은 경우가 많다. (항상 그런 것은 아니다)