
개요
Spring Cloud란?
Spring Cloud
- 마이크로서비스 아키텍처(MSA)를 지원하기 위해 다양한 도구와 라이브러리를 제공하는 프레임워크
- 분산 시스템과 클라우드 환경에서 애플리케이션을 효과적으로 개발하고 운영할 수 있는 기능을 제공
- VMWare, 하시코프(HashiCorp), 넷플릭스 등 오픈 소스 회사의 제품을 전달 패턴으로 모아 놓은 도구들의 집합
Netflix OSS(Open Source Software)
- Netflix에서 개발한 오픈소스 소프트웨어들의 집합
- 클라우드 네이티브 애플리케이션을 만들기 위한 다양한 도구들을 자체적으로 사용 및 검증하여 라이브러리로 제공함
- 대표적인 도구로는 Eureka, Hystrix, Ribbon, Zuul 등이 존재
Spring Cloud의 특징
API 게이트웨이(API Gateway)
서비스 간의 통신을 중앙에서 관리하는 서버. 주로 라우팅, 인증, 보안, 로드 밸런싱, 캐싱 등의 기능을 담당한다.
- Zuul: Netflix OSS 기반의 API 게이트웨이. 요청 라우팅, 필터링, 보안 등의 기능을 제공한다.
- Cloud Gateway: 스프링 클라우드에서 제공하는 API 게이트웨이. 비동기 및 논블로킹 방식으로 동작하여 Zuul 보다 더 높은 성능을 제공한다.
서비스 디스커버리(Service Discovery)
서비스들의 위치와 상태를 자동으로 찾고 관리하는 기능. 서비스는 자동으로 디스커버리 시스템에 등록되고 종료되면 자동으로 해제된다. client는 이를 통해 동적으로 사용 가능한 서비스를 검색하고 선택한다.
- Eureka: Netflix OSS 기반의 서비스 디스커버리 도구. 서비스 인스턴스가 실행될 때 자동으로 등록되며, 클라이언트는 Eureka 서버를 통해 서비스의 위치를 조회할 수 있다.
분산 설정(Distributed Configuration)
설정을 중앙에서 관리하고 업데이트하는 기능. 서비스는 해당 서버에서 설정을 동적으로 가져와 사용하며, 이는 서비스를 중단하지 않고 실행 중일 때 변경해도 즉시 적용할 수 있도록 한다.
- Spring Cloud Config: 중앙 집중식 구성 관리를 제공하는 프레임워크. Spring Cloud Bus를 사용하면 서비스 재시작 없이도 설정 반영이 가능하다.
분산 추적(Distributed Tracing)
트랜잭션 추적을 위한 기능. Spring Cloud Sleuth를 통해 발생한 작업을 기록하여 마이크로서비스 간의 요청과 응답을 추적하고 모니터링하는 데 사용한다.
- Zipkin: 각 요청에 고유한 추적 ID를 부여하여 요청의 흐름을 시각화할 수 있다. 요청의 시작부터 끝까지의 경로를 추적하여 지연 시간, 오류 등의 정보를 수집한다. 또한 특정 요청을 검색하고 필터링하여 문제를 진단할 수 있다.
로드 밸런싱(Load Balancing)
여러 서버에게 들어오는 트래픽을 균등하게 분배하여 부하를 분산. 세션 유지, scale out 과 같은 기능을 통해 네트워크 트래픽을 효과적으로 관리한다.
- Ribbon: Eureka와 연동하여 서비스 인스턴스 목록을 가져와 동적으로 로드 밸런싱을 수행할 수 있다. 클라이언트는 Ribbon을 통해 여러 개의 인스턴스 중 하나를 선택하여 요청을 보내는 방식으로, 분산 전략으로 라운드 로빈, 가중치 기반 등 다양한 알고리즘을 지원한다.
회로 차단기(Circuit Breaker)
서비스 간의 통신에서 발생할 수 있는 장애에 대응하는 메커니즘. 서비스 간 통신이 실패할 경우 일시적으로 연결을 차단하여 전체 시스템에 영향을 최소화하고, 일정 시간 이후에 재시도하거나 다른 대체 서비스를 호출한다.
- Hystrix: Netflix OSS 기반의 서킷 브레이커 라이브러리
- Resilience4j: Hystrix의 대체 도구로, 경량화되고 모듈화된 자바 기반의 서킷 브레이커 라이브러리. 특정 임계치를 초과한 요청을 차단하고, 일정 시간이 지나면 다시 정상 동작을 시도할 수 있다. 실패 시 Failback 매커니즘을 통해 대체 동작을 수행한다.
기술 비교
Spring Cloud vs Spring Boot
- Spring Boot와 Spring Cloud는 모두 Spring Framework 기반으로 개발이 되었지만 각각의 목적과 기능의 차이가 있음
- Spring Boot: ‘단일 애플리케이션 개발’을 위한 프레임워크
↔ Spring Cloud: ‘분산 시스템의 개발 및 운영’을 위한 프레임워크 - Spring Cloud는 Spring Boot에서 제공하는 기능을 기반으로 분산 시스템에서 필요한 다양한 기능들을 추가로 제공함
⇒ Spring Cloud라는 환경 하에 각각의 단일 애플리케이션은 Spring Boot를 이용하여 개발
Gateway vs Load Balancing
- gateway
- 정해진 규칙에 따라 들어온 요청을 올바른 서비스에 라우팅하는 역할
- 로깅, 요청 URL 수정, 인증/권한 처리, 헤더 변경, 요청과 응답 필터링 등, 클라이언트와 서비스 사이에서 더 세밀한 처리가 가능
- GW는 LB처럼 트래픽 부하를 조절하는 역할은 없음
- load balancing
- 인스턴스 간 트래픽 분배를 통해 서버나 컨테이너의 부하를 관리하는 역할
- LB는 GW처럼 요청에 대해서 추가적인 처리를 하지는 않음
Config server
Spring Cloud Config
- 개념
- 분산된 환경에서 중앙 집중식 설정 관리를 제공
- config 서버/클라이언트
- server: 중앙에서 설정 파일을 관리하고 각 서비스에 제공하는 역할
- client: config 서버에서 설정을 받아 사용하는 서비스
- 설정 자동 갱신
- 설정 변경 시 서버 재시작 없이 실시간으로 변경 사항을 반영 가능
- 이를 통해 시스템의 중단 없이 즉시 변경 사항 적용 가능
Config 서버 로직
애플리케이션 구동 요청이 들어오면 Config 서버를 통해서 서버 실행에 필요한 설정 값들을 가져온다.그림에서는 설정 정보를 Git Repository에 저장하고 있지만, DB에 저장할 수도 있다.

config_server_application.yml 예시
spring:
### 애플리케이션 관련 설정 ###
applcation:
name: config-server
profiles: # 활성화할 Spring Profile을 설정
active: json # json 프로파일을 활성화하여 JSON 형식으로 구성된 파일을 사용하도록 설정
### DB 관련 설정 ###
datasource:
hikari:
pool-name: CONFIG-DB-POOL # DB 연결 풀의 이름. 연결 풀을 구분하는 데 사용됨
driver-class-name: org.maradb.jdbc.Driver
jdbc-url:
username:
password:
maximum-pool-size: # 동시에 사용할 수 있는 DB 연결의 최대 개수
connection-timeout: 5000 # DB에 연결 시 최대 대기 시간
validation-timeout: 3000 # 연결이 정상인지 확인하는 동안 대기하는 시간
idle-timeout: 60000 # 연결이 유휴 상태일 때 연결 풀에서 제거되기 전까지 대기하는 시간
max-lifetime: 180000 # DB 연결의 최대 생명 주기. 이 시간이 지난 연결은 풀에서 제거됨(idle 상태와 무관)
data-source-properties: # 추가적인 데이터베이스 연결 설정
cachePrepStmts: true # PreparedStatement 캐싱을 활성화하여 성능을 최적화
prepStmtCacheSize: 500 # 캐시의 SQL 크기 제한
prepStmtCacheSqlLimit: 2048
useServerPrepStmts: true # 서버에서 PreparedStatement를 사용하는 옵션을 활성화
### spring cloud 관련 설정 ###
cloud:
config:
server:
jdbc:
sql: SELECT ~~ # config 조회 요청 시 실행되는 쿼리
order: 1
Service Discovery
Eureka
- 개념
- 클라이언트가 서비스 인스턴스를 동적으로 찾을 수 있도록 지원
- 서비스의 등록과 검색을 자동화하여 애플리케이션의 복잡성을 줄여줌
- 서비스 레지스트리 (Service Registry)
- Eureka는 서비스 레지스트리로 작동하여 모든 서비스 인스턴스의 위치를 중앙 저장소에 저장함
- 각 서비스는 Eureka 서버에 자신의 위치(호스트 및 포트 정보)를 등록하고, 이러한 정보를 조회하여 통신할 수 있음
- 헬스 체크(Health Check)
- 서비스 인스턴스의 상태를 주기적으로 확인하는 헬스 체크 기능을 제공
- 서비스 인스턴스는 주기적으로 자신을 등록한 Eureka 서버에 헬스 체크 정보를 보내며, Eureka는 이를 기반으로 서비스의 가용성을 판단함
Discovery 서버 로직
1. 서비스 등록
위에서 살펴본 config 서버가 같이 나와있다. gateway 서버도 결국 하나의 서비스이기 때문에, 최초 구동 시 config 서버를 통해 설정값을 읽어와야 정상적으로 실행된다. 자세한 내용은 아래에서 설명할 예정이므로, 여기선 간단히 client의 API 요청을 라우팅한다고만 알고 있으면 된다. discovery(eureka) 서버를 제외한 나머지 서비스들은 자신의 정보를 사전에 알려줘야 한다. 이 과정이 서비스 등록 단계이다.

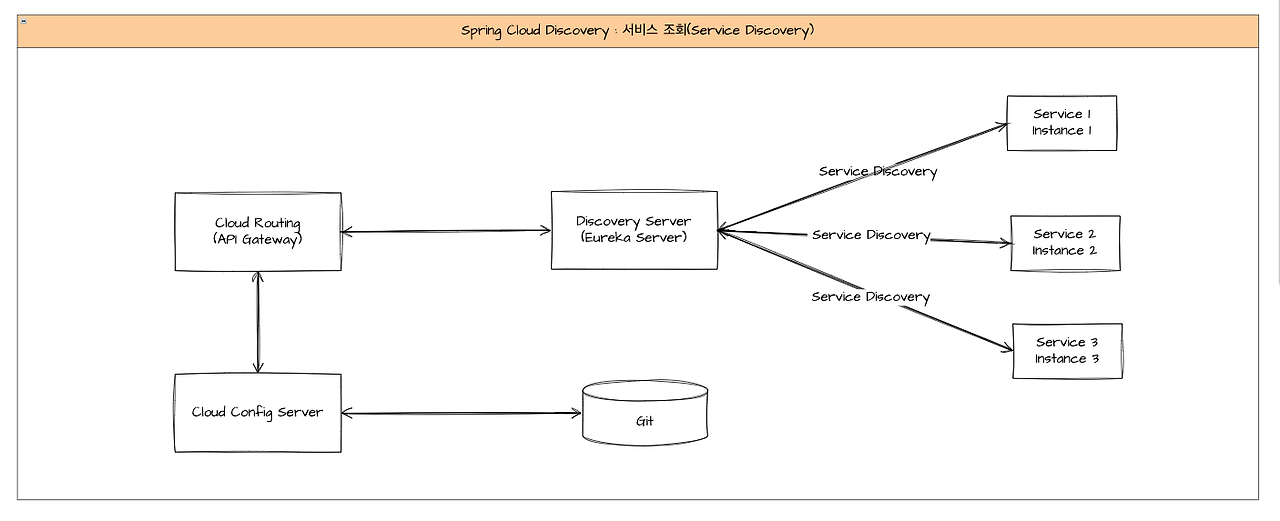
2. 서비스 조회
client가 gateway에 API 요청을 보내면 gateway는 URL에 해당하는 인스턴스 정보를 찾고 이를 전달해야 한다. 해당 정보를 찾기 위해 discovery 서버와 통신하여 요청을 라우팅할 서비스를 조회한다.
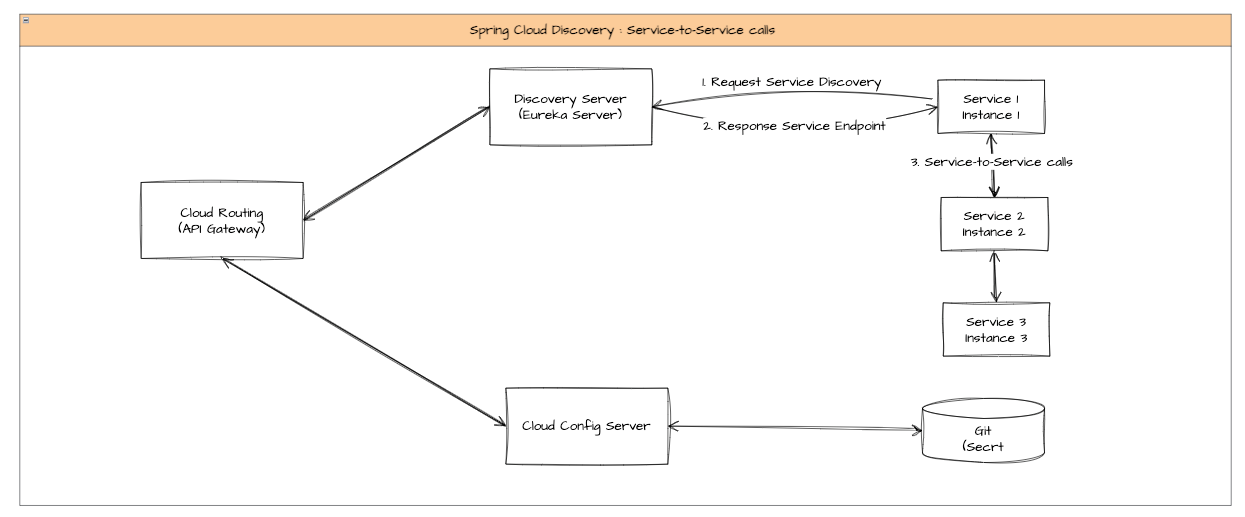
3. 서버 간 통신
2번과 동일하게 요청이 Service1에 전달되었다고 해보자. 그런데 해당 서비스에서 모든 작업을 처리한 후 바로 리턴될 수도 있지만, 그 과정에서 서로 다른 서비스 간에도 요청을 주고받을 수 있다. 이 경우에도 로직은 위와 동일하다. service1에서 service2로 요청을 보내고자 할 때, discovery 서버에게 service2에 대한 정보를 요청하게 되고 endpoint를 리턴값으로 받게 된다. 이를 활용해서 서버 간에 다시금 요청을 보내며 통신할 수 있다.
discovery_server_application.yml 예시
discovery 서버는 각 인스턴스의 정보를 저장하는 "서버"와, 기타 나머지 "client"들이 존재한다. 서버와 클라이언트의 yml 파일에서 설정해주는 값이 서로 다르다.
####################### EUREKA SERVER
eureka:
### Eureka 서버 관련 설정 ###
server:
enable-self-preservation: true # 자기 보호 모드 활성화
response-cache-update-interval-ms: 5000 # 응답 캐시 갱신 주기
activation-interval-timer-in-ms: 1000 # client로부터 활성화 여부 확인 주기
### Eureka 클라이언트 관련 설정 ###
client:
register-with-eureka: false # Eureka 서버에 서비스 등록 여부
fetch-registry: false # Eureka 서버에서 다른 서비스 목록을 가져오지 않음
registry-fetch-interval-seconds: 2 # Eureka 서버에서 서비스 정보를 가져오는 주기
service-url:
defaultZone: <http://localhost:8761/eureka/> # Eureka 서버의 기본 주소
### Eureka 인스턴스 설정 ###
instance: # 인스턴스란 서버 또는 컨테이너 단위
prefer-ip-address: true # 호스트명 대신 IP 주소를 사용해 Eureka에 등록
ip-address: {hostIP} # 환경변수로 IP 지정
####################### EUREKA CLIENT
eureka:
instance:
prefer-ip-address: true
ip-address:
lease-renewal-interval-in-seconds: 1
# 설정된 시간 안에 하트비트가 안오면 등록 해제. 정상종료의 경우 즉시 해제
lease-expiration-duration-in-seconds: 5
client:
register-fetch-interval-seconds: 2
register-with-eureka: true
fetch-registry: true
service-url: ~
defaultZone: ~
Gateway Server
Zuul
- 개념
- 넷플릭스가 개발한 API 게이트웨이로, 모든 서비스 요청을 중앙에서 관리
- 특징
- 라우팅: client의 요청 url에 따라 적절한 백엔드 서비스로 요청 전달
- 필터: 요청 전후 다양한 작업을 수행할 수 있는 필터 체인을 제공. 인증/권한 부여/로깅 등을 처리
- 모니터링: 요청 로그 및 메트릭을 통해 서비스의 상태를 모니터링 가능
Gateway 서버 로직
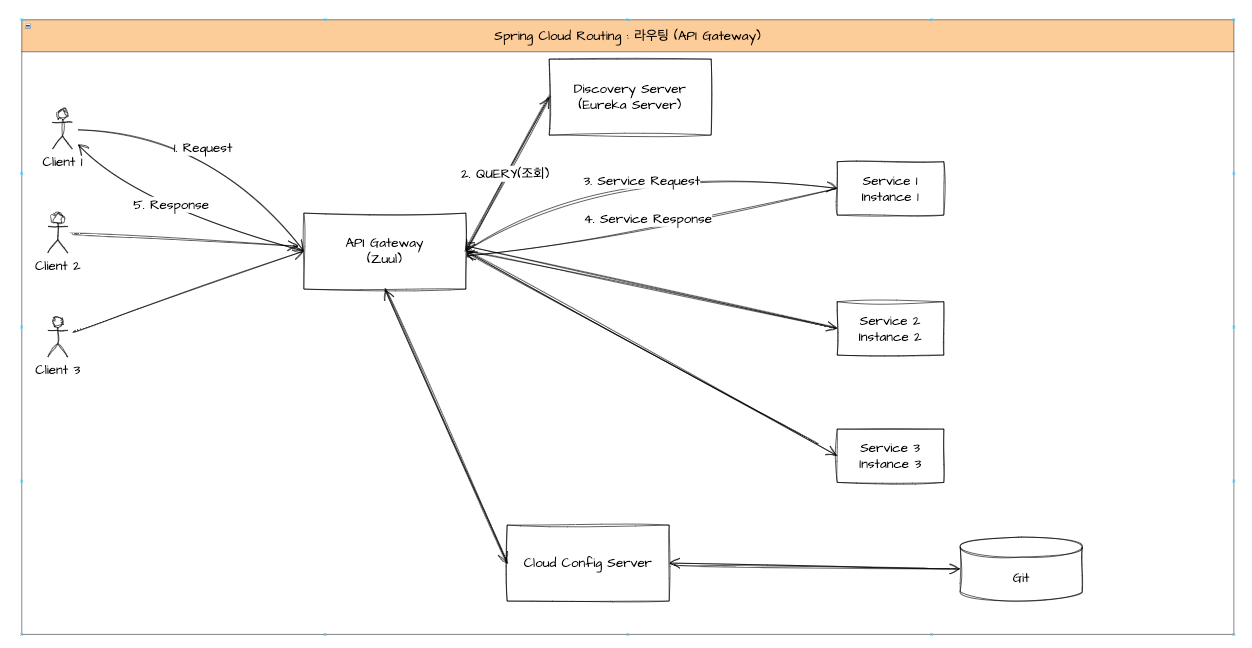
위 discovery에서 보던 그림과 로직은 동일하며, client 그림이 추가되었을 뿐이다. 모든 API 요청은 gateway를 통하게 된다.
gateway_server_application.yml 예시
gateway 기능을 제공하는 라이브러리는 Spring Cloud Gateway와 zuul이 있다. zuul을 보면 routes에서 service-id만으로 간단하게 URL을 정의하고 있는데, 이 값은 discovery 서버의 정보에서 찾을 수 있다. 각 서비스가 discovery 서버에 자신의 정보를 등록할 때 전달한다.
####################### Spring Cloud Gateway
spring:
cloud:
gateway:
### HTTP client 설정 ###
httpClient:
pool:
max-connections: 200
max-idle-time: 30s # 최대 유휴 시간
max-life-time: 60s # 커넥션 최대 생명 주기
connect-timeout: 3000
response-timeout: 20s
# x-forwarded 헤더 관련 설정
x-forwarded:
enabled: true # x-forwarded 헤더 사용 여부 (true로 설정하면, 요청에 x-forwarded 관련 헤더가 추가됨)
### 라우팅 설정 ###
routes:
- id: A-SERVICE
uri: lb://A-SERVICE # 서비스의 URI (부하 분산을 위한 lb:// 접두어 사용)
predicates:
Path=/cc/** # 경로 조건
filters:
- RewritePath=/aa$, /aa/ # 경로 재작성 필터 ("/aa"를 "/aa/"로 변경)
- CustomFilter # 사용자 정의 필터
- id: B-SERVICE
uri: lb://B-SERVICE
predicates:
Path=/bb/**
filters:
- RewritePath=/bb/(?<segment>.*), /$\\{segment} # "/bb/segment"를 "/segment"로 변경)
- CustomFilter
####################### zuul
zuul:
sslHostnameValidationEnabled: false # SSL 호스트명 인증서 검증 비활성화
ignored-headers: Access-Control-Allow-Credentials # 무시할 헤더 목록. 라우팅 시 전달x
sensitive-headers: # 민감한 헤더 목록
host:
connect-timeout-millis: 60000
socket-timeout-millis: 60000
routes:
OCR-ADMIN:
path: /aa/**
service-id: A-SERVICE
OCR-BATCH:
path: /bb/**
service-id: B-SERVICE
Load Balancing
Ribbon
- 개념
- Neflix가 개발한 클라이언트 사이드의 로드 밸런싱을 지원하는 도구로, 서비스 인스턴스 간의 부하를 효과적으로 분산시킬 수 있음
- 특징
- 서버 리스트 제공자(Server List Provider)
- 디스커버리 서버로부터 서비스 인스턴스의 리스트를 제공받아, 이를 통해 서비스 인스턴스의 위치와 상태를 동적으로 업데이트하며 로드 밸런싱에 필요한 최신 정보를 유지함
- 로드밸런싱 알고리즘 (Load Balancing Algorithms)
- 라운드 로빈(Round Robin)과 가중치 기반(Weighted) 등 다양한 로드 밸런싱 알고리즘을 제공함. 라운드 로빈은 요청을 순서대로 분산시키고, 가중치 기반 로드 밸런싱은 각 인스턴스의 처리 능력에 따라 트래픽을 분산시킴
- Failover
- 요청 실패 시 자동으로 다른 서비스 인스턴스로 전환하는 기능. 만약 특정 인스턴스가 응답하지 않거나 오류가 발생하면 다른 가용 인스턴스를 선택하여 요청을 처리함
load_balancing_application.yml 예시
ribbon:
ServerListRefreshInterval: 1 # 서버 목록을 1ms마다 새로고침
ReadTimeout: # 서버 응답 대기 최대 시간
SocketTimeout: # 서버와의 연결 유지 시간
MaxTotalHttpConnections: 2000 # 전체 서버에 대해 허용할 최대 HTTP 연결 수
MaxConnectionsPerHost: 2000 # 개별 서버(호스트)당 허용할 최대 HTTP 연결 수
'Backend > spring' 카테고리의 다른 글
| Jasypt 라이브러리로 .env 변수값 암호화 (0) | 2025.05.16 |
|---|