리눅스의 파일 권한
일반 파일 권한

- 모든 파일과 디렉터리는 접근 권한과 소유권이 부여됨
- 사용자별 권한은 기호 모드(symbloic)와 8진수 숫자 모드(numeric)로 표시
- ls -al 결과 표시 내용: 파일 유형 + 접근 권한, 물리적 파일 연결개수(하드링크), 소유자, 소유 그룹, 크기, 마지막 변경 날짜+시간, 파일명
- 디렉토리의 x 권한: 해당 디렉터리 안에서 작업이 가능하다는 의미
리눅스 파일의 특수 권한
- 프로세스가 실행되는 동안 해당 프로세스의 root 권한을 임시로 가져오는 기능
- 프로세스가 사용자보다 높은 수준의 접근을 요구할 때 접근 제한 때문에 원활한 기능을 제공할 수 없기 때문에 이를 해결하기 위함
- SetUID: 사용자가 소유할 때만 소유자 권한으로 파일을 실행 시킴
- SetGID: 소유자 그룹 권한으로 실행
- s(실행파일), S(일반 파일)
- 예시: 일반 계정의 비밀번호를 변경할 경우, root 권한으로 /etc/passwd 파일 접근
Sticky Bit
- 주로 공용 디렉터리를 사용할 때 사용
- 폴더에 대하여 소유자 혹은 root만 파일을 수정하거나 삭제 가능
chmod +t tmp
ls -al
> drwxrwxr-t root root 4096 tmp
디스크 쿼터(Disk Quota)
- 파일 시스템마다 사용자나 그룹이 생성할 수 있는 파일의 용량 및 개수를 제한하는 것
- 주로 block 단위의 용량 제한과 inode의 개수를 제한함
- 쿼터는 사용자별, 파일 시스템별로 동작함
- 디스크 쿼터 설정 파일 및 관련 명령어
- quotaoff: 쿼터 서비스 비활성화
- qoutaon: 활성화
- quotacheck: 파일시스템의 디스크 사용 상태 점검
- edquota: 편집기를 이용한 사용자/그룹 쿼터 설정
- setquota: 명령어를 이용한 사용자/그룹 쿼터 설정
권한 및 그룹 설정 명령어
chown
- 사용자(그룹) 소유권 변경
- -R 옵션: 하위 디렉터리도 동일하게 변경(소유권의 상속)
chown root:root test.txt
chown root test.txt # 소유자
chown :root test.txt # 소유 그룹
chgrp
- 소유 그룹 변경
- chgrp <옵션> [그룹명] [파일명]
- -R: 하위 디렉터리 포함
chmod
- 접근 권한 변경
- chmod <옵션> [권한] [파일명]
- -R: 하위 디렉터리 포함
chmod +x file # 모든 유저에게 실행 권한 추가
chmod -x file
chmod u+x file # 소유자에게 실행 권한 추가
chmod g=rx file # 그룹에 read, write권한 추가
chmod o-x file # 기타 다른 사람들은 실행할 수 없도록 설정
chmod a+r file
chmod 766 file # rwx를 이진수로 계산한 것
unmask
- 파일/디렉터리 생성 시 기본으로 적용할 접근 권한을 지정
- 파일은 (666 - umask값), 디렉터리는 (777 - umask) 값으로 설정됨
- umask <옵션>[설정값]
- -S: 문자로 표시
umask # 기존값 조회
umask 002 # umask값 설정
파일 시스템의 관리
파일 시스템의 개요
- 파일 시스템이란? 스토리지 장치(디스크) 상에 파일을 관리할 수 있도록 만들어 놓은 구조 혹은 관리 방식
- 최근에는 서버 파일과 가상 파일까지 접근할 수 있도록 개념이 확대됨

- 슈퍼 블록: 파일 시스템 관련 정보(블록 크기 및 개수, inode 개수)
- Group Descriptor: 각 블록 그룹을 관리하는 정보를 저장
- Block Bitmap: 블록의 사용 상태를 나타냄
- inode: 파일 이름을 제외한 정보(고유 번호, 파일 형태, 크기, 위치, 소유자 등)
- inode bitmap: inode의 상태 정보
- inode table: 각 inode에 대한 정보를 나타내는 descriptor로 구성
파일 시스템의 종류
저널링이란?
- 로그와 유사한 개념
- 특정 정보 관리를 통해 파일 시스템에 문제가 생길 경우 복구 진행
1. 저널링 파일 시스템

2. 네트워크 파일 시스템

3. 지원 가능한 기타 파일 시스템

파일 시스템 관련 명령어
/etc/fstab 파일
- 파일 시스템 정보 저장 및 관리하는 설정 파일
- 부팅 시 마운트 정보 포함
mount
- 스토리지 장치를 연결하여 디렉토리처럼 사용
- 설정 파일: /etc/fstab(부팅 시 참조하여 마운트), /etc/mtab(마운트된 블록 시스템 정보)
- mount <옵션> [장치명] [디렉터리명]

unmount
- 마운트 해제
- unmount <옵션> [장치명] [디렉터리명]

eject
- 미디어 장치를 해제하고 장치를 제거
- eject <옵션> [디바이스명]
fdisk
- 새로운 파티션의 생성, 기존 파티션의 삭제, 파티션의 타입 결정
- 한 번에 한 디스크에 대해서만 작업을 수행
- fdisk <옵션> [디바이스명]
- fdisk를 실행하기 위해서는 어떤 디스크의 파티션을 나눌 것인지 지정 필요
mkfs
- 파일 시스템 생성
- 파티션 생성 뒤 원하는 파일 시스템 구축 필요
- mkfs <옵션> [디바이스명]

mkfs2
- ext2, 3, 4 리눅스 파일 시스템 생성
- mkfs2 <옵션> [디바이스명]

fsck
- 파일 시스템 점검 및 복구
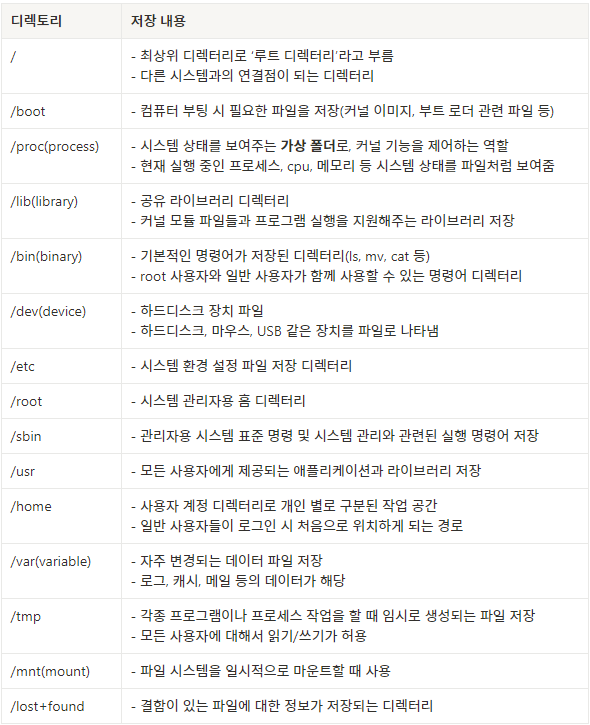
- /lost+found 디렉터리에 손상된 파일 관리 → 정상 복구된 후 삭제됨
- fsck <옵션> [디바이스명]

e2fsck
- ext2, 3, 4 리눅스 파일 시스템 점검 및 복구
- e2fsck <옵션> [디바이스명]

du(disk use)
- 디렉터리 별 디스크 사용량 확인
- du <옵션> [디바이스명]

df
- 시스템에 마운트된 하드 디스크의 남은 용량을 확인
- 파티션 단위로 사용량 확인
- 기본 1024bte 블록 단위로 출력
- df <옵션> [디바이스명]

References
'Etc' 카테고리의 다른 글
| 리눅스 마스터 2급 정리(8) - 에디터 활용과 프로그램 설치 (0) | 2025.05.10 |
|---|---|
| 리눅스 마스터 2급 정리(7) - Shell과 환경 설정 (0) | 2025.05.06 |
| 리눅스 마스터 2급 정리(5) - 네트워크+기타 명령어 (0) | 2025.05.06 |
| 리눅스 마스터 2급 정리(4) - 디렉터리 및 파일 관련 명령어 (0) | 2025.05.02 |
| 리눅스 마스터 2급 정리(3) - 사용자 생성 및 계정 관리 명령어 (0) | 2025.05.02 |