POSIX(Portable Operation System Interface) 표준 기반으로 유닉스와 호환 가능
안정적인 동작
swap 방식을 통한 효율적인 하드웨어 활용
단점(최근에는 많이 보완됨)
오픈소스로 기술 지원의 한계 존재
보안 상 취약점 노출 가능성
한글 지원 미흡
배포판의 종류와 특징
💡 리눅스 배포판이란? 리눅스 커널, GNU 소프트웨어, 응용 프로그램 등을 함께 묶어서 구성한 리눅스 OS. 목적에 따라 다양한 배포판이 존재함
슬랙웨어 리눅스: 1992년에 등장하여 가장 먼저 대중화
데비안: GNU의 공식 후원을 받는 유일한 배포판
우분투: 데비안 GNU/리눅스에 기초. 사용자 편의성에 초점을 맞춤
레드햇
RHEL(기업용): subscript 형태로 요금을 지불
페도라: 레드햇과 커뮤니티의 지원으로 개발
CentOS: RHEL과 완벽하게 호환, 무료 기업용 OS
수세(Suse): 독일에서 출시된 배포판으로 유럽에서 인기
리눅스의 역사
켄 톰슨: 유닉스 개발(어셈블리 언어 기반, 호환성 이슈 존재)
데니스 리치: UNIX를 C언어로 재개발. 이후 BSD 계열과 시스템 V 계열로 분리
리처드 스톨먼: 시스템 V측의 소스 코드 비공개 및 상업적 이용 제한에 반발하여 GNU 프로젝트 시작
앤드류 타넨바움: 미닉스 개발(오픈소스)
리눅스 토발즈: 미닉스의 커널 소스를 수정하여 GNU 시스템에 적합한 커널을 제작(+유닉스와 호환)
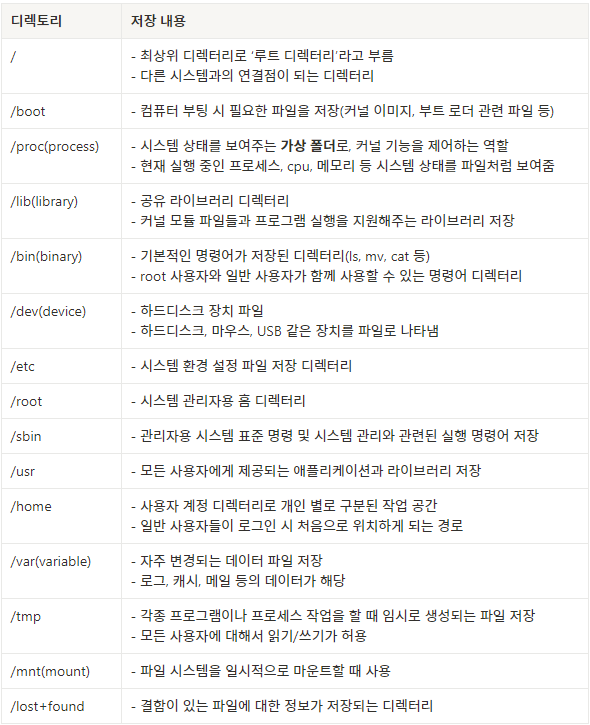
디렉터리 종류와 특징
💡/bin vs /usr/bin - /bin: 시스템 부팅 및 복구에 필요한 최소한의 필수 명령어 저장 (ex: ls, cp, mv, cat, sh, mkdir) - /usr/bin: 부팅 후 일반 작업에 필요한 다양한 명령어 저장 (ex: vim, python, gcc, tar, curl)
리눅스 설치
리눅스 설치 개요
리눅스의 종류가 다양하고, 배포판마다 설치 환경 및 과정이 다름
설치 유형은 데스크탑형, 서버형, 사용자 정의형(취향에 따라 설치)으로 구분됨
하드디스크 재구성이 진행되기 때문에 백업 필수
부팅 드라이브를 다시 파티션하는 경우라면 os의 부트 로더를 다시 설치해야 할 수 있음
파티션
💡 파티션이란? - 하나의 물리적 디스크를 여러 개의 논리적인 디스크로 분할하는 것 - 각 파티션마다 독립적인 파일 시스템을 만들 수 있음 → 관리 효율성 증가(부팅 시간, 오류 점검, 백업/복구 시간 단축) - 시스템 손상 시 영향 최소화
디스크와 장치명
파티션 이름: 디스크의 장치 파일명 + 숫자
/dev/hda3 → /dev + /hd + 3
/dev: 시스템 디바이스 파일들이 저장되는 디렉터리
/hd: IDE 혹은 ATA 방식 /sd: SCSI 혹은 USB 방식
a: 하나의 케이블에 연결된 디스크의 우선순위
3: 파티션 번호
마운트 시 지정된 장치명을 사용(ex: /dev/hda)
파일 시스템
파일 시스템은 디스크의 파티션에 파일을 사용할 수 있도록 구성해놓은 것 또는 구성 방식
리눅스는 고유 파일 시스템 뿐 아니라 다양한 파일 시스템을 지원하고 있음
파일 시스템의 종류
리눅스 전용(ext1~4)
저널링 파일 시스템(JFS, XFS): 파일 시스템에 오류가 생기더라도 복구가 가능하도록 만든 것
네트워크 파일 시스템(SMB, NFS): 다른 pc에 있는 파일 시스템을 내 것처럼 쓸 수 있도록 함
클러스터링 파일 시스템(GFS)
장치 파일 시스템(IS9660, UDF)
OS별 파일 시스템(윈도우: FAT32, NFTS/NET OS: HPFS)
LVM(Logical Volume Manager)
작은 용량의 하드디스크 여러 개를 큰 용량의 하나의 하드디스크처럼 사용
다수 개의 디스크를 묶어 사용함으로써 파티션의 크기를 유연하게 조절할 수 있음
LVM 구성 볼륨의 종류
물리 볼륨: 개별 물리적인 디스크
볼륨 그룹: 여러 개의 물리 볼륨을 하나의 그룹으로 구성
논리 볼륨: 볼륨 그룹의 일부를 논리 그룹으로 나누어 사용
RAID(Redundant Array of Independent Disks: 복수 배열 독립 디스크)
💡 LVM vs RAID - LVM은 단순히 용량을 늘리는 것이 목적 - RAID는 시스템 에러 발생 시 가용성을 보장하는 것이 목적(안정성)
여러 개의 물리적 디스크를 하나의 논리적 디스크로 인식하여 작동하게 하는 기술
특징: 데이터 분할 저장, 데이터 중복 저장, 오류 관리 → 고용량, 신뢰성, 성능 향상
RAID의 종류
하드웨어 RAID: 하드웨어 제작 업체에서 장비 자체를 여러 디스크를 꽂을 수 있도록 구성. 안정적
소프트웨어 RAID: 하드웨어보다 저렴하지만 안정성은 떨어짐
구성(데이터 저장) 방식에 따라 레벨을 붙임. 숫자가 클수록 신뢰성이 높거나 성능이 향상됐음을 의미
RAID 0(스트라이핑 방식): 여러 디스크에 데이터를 나눠 저장 → 고용량, 빠른 I/O but 고장에 취약
RAID 1(미러링 방식): 디스크에 중복 데이터 저장 → 결함 허용 but 저장 공간 2배 필요
RAID 0 + 1: 스트라이핑 후 미러링 → 빠른 I/O but 느린 복구 시간
RAID 1 + 0: 미러링 후 스트라이핑 → 손실된 데이터의 빠른 복원
fdisk
fdisk란 파티션 테이블을 관리하는 명령어
리눅스의 디스크 파티션을 생성, 수정, 삭제할 수 있는 일종의 유틸리티
fdisk [장치명] 입력 후 명령어 입력
부트 로더(Bootstrap Loader) = 부트 매니저
컴퓨터를 사용자가 사용할 수 있도록 디스크에 저장된 OS를 주기억장치로 적재해주는 프로그램
필요한 초기 작업, OS(멀티부팅)을 주 메모리로 복사, 운영체제 실행 등의 기능을 수행
부트 로더의 저장 위치
MBR(Master Boot Record): 하드디스크의 첫 번째 섹터로, 디스크 전체에 1개만 존재함. 512Byte의 크기로, 파티션 테이블 정보를 저장함. 어느 파티션을 부팅할지 설정하고 해당 섹터로 점프하는 역할
각 주 파티션의 부트 섹터: 해당 파티션의 첫 번째 섹터(부트 섹터). os 커널을 메모리에 로드하는 역할
임베디드 시스템 부트로더: PC BIOS와 OS Loader 기능을 수행하는 프로그램으로, 시스템 부팅 시 가장 먼저 수행됨
부트로더의 종류
LILO(Linux Loader): 리눅스 전용
GRUB2(Grand Unified Bootloader version2)
리눅스 뿐 아니라 다른 os에서도 사용 가능
편리한 설정 및 사용, 대화형 UI 가능
부팅 시 부트 정보 수정. 멀티 부팅 지원
파일 시스템과 커널 실행 형식 인식 후 부팅
런레벨
리눅스 시스템 부팅 시 어떤 서비스를 자동으로 시작할지 결정하는 단계
0~6개까지 7개의 단계가 존재하며, /etc/inittab 파일에서 설정 가능([런레벨]:[행동]:[명령어] 형식)
주로 3, 5레벨이 많이 사용됨
로그인과 로그아웃
로그인
리눅스는 X윈도우 상에서 로그인/로그아웃과 콘솔상에서의 로그인/로그아웃이 있음
로그인 과정
패스워드 확인 → 입력한 패스워드와 /etc/passwd 필드 비교
쉘 설정 파일 실행 → PATH 경로, 터미널 설정, 환경변수, 로그인 시 실행 명령, 로그인 메세지 출력
옛날에 은행이 처음 전산화되던 시절에는 슈퍼컴퓨터가 사용되었다. IBM에서 만든 메인 프레임을 도입했고, 은행 거래에서 발생하는 수많은 입출금 데이터들을 이 곳에 저장했다. 이것이 은행의 최초의 전산화된 컴퓨터였고, 처음에 들어온 이 시스템을 은행 코어 시스템이라고 한다. 코어계, 기반계, 계정계라고도 부른다. 즉 은행에서 가장 중요한 부분을 담당하는 것이다. 여기에 주로 사용되는 언어는 COBOL, PL/1이었다. 그 옛날에 전공책에서나 보던 천공 카드에 구멍을 뚫던 시절이었다.(참고 블로그)
정보계의 등장
이렇게 데이터가 저장되면, CEO와 같은 대표들은 이 데이터를 활용한 통계 자료를 보고 싶어할 것이다. 어제 돈이 얼마가 들어왔고 고객이 얼마나 이용했는가? 단순히 생각하면 어려운 일은 아니다. 그냥 DB에 select group by하면 쉽게 결과가 나올 것이다. 하지만 해당 시스템은 계속해서 고객들의 돈이 거래되고 있다는 점이 문제다. 성능은 한정되어 있기 때문에 계속해서 거래가 이루어지고 있는 메인 프레임에 추가적인 처리를 요청하는 것은 시스템에 부하를 줄 수 있다.
그래서 계정계와 동일한 시스템과 DB를 복제해서 그러한 부수적인 업무만을 수행하도록 정보계를 만들었다. 당시에는 DB를 실시간으로 복제하는 기술이 없었기 때문에 하루 정도는 딜레이가 있었다. 이를 디퍼드(Deferred) 시스템이라고 한다. 디퍼드 시스템이란 동일 기종인 메인 프레임끼리 데이터를 (정보계로) 전송하는 것을 뜻하며, deferred의 의미 그대로 지연돼서 처리되는 것으로 이해하면 된다.
UNIX와 다운사이징
인터넷이 발달하며 이제는 사용자 친화적인 웹 UI가 일반적이지만, 아직도 메인 프레임을 쓰는 기업들이 있다. 코스트코에 가보면 아직도 직원들이 검은 화면에 SSH같은 터미널을 이용하는 모습을 볼 수 있다. 왜 아직도 메인 프레임을 쓰는 걸까? 효율이 매우 좋기 때문이다. KB은행도 아직 메인 프레임을 사용하고 있다. (SC제일은행은 추진?)
그런데 메인 프레임은 치명적인 단점이 있다. 비용이 너무 비싸다는 것이다. 은행이 비싼 IBM 금액을 부담으로 느끼던 와중, 유닉스(c/c++ 기반)와 이를 기반으로 한 다양한 프레임워크가 등장했다. 은행은 비용 절감을 위해 IBM의 메인 프레임에서 유닉스로 다운사이징을 하게 되었다. 성능이 조금 떨어지더라도 비용을 아끼는 것이다. 유닉스 환경으로 교체하기 위해서는 기존의 코볼과 PL/1에서 c언어 기반으로 바꿀 필요가 있었다. TMAX에서 개발한 proframe는 c언어 기반의 프레임워크를 제공하며, 실제 많은 은행에서 차세대 프로젝트에 해당 기술을 도입되었다. 코어계는 중요한 부분인 만큼 건들기 어려우니 정보계부터 유닉스로 바뀌게 되었고, 안정성이 검증되자 코어계도 서서히 바꾸기 시작했다. 이렇게 다운사이징하는 것을 금융권 차세대 프로젝트라고 한다.
KB은행의 차세대?
IBM의 메인 프레임도 일정 기간이 지나면 장비를 교체해야 한다. KB은행은 장비를 교체할 경우 IBM의 지원을 받기 위한 비용과, 다운사이징을 위해 시스템을 전부 c언어 기반으로 교체하는 데 드는 비용 2가지를 비교해 보았다. 그 결과 다운사이징 경우가 더 저렴한 것으로 판단히고 유닉스 시스템으로 전환하기로 결정했었다. (2012년부터 검토, 결정 후 2013년 10월에 금감원에 보고) 물론 비용뿐 아니라 IBM은 시스템 개방성이 떨어진다는 문제 등 다양하게 고려한 결과였다.
다시 돌아와서, 유닉스의 등장으로 많은 시중 은행들은 메인 프레임에서 유닉스로 다운사이징 차세대를 진행했다. 그러다 이후에는 훨씬 더 저렴한 (자바 기반의) 리눅스가 등장하게 된다. 심지어 리눅스는 오픈소스라는 장점도 갖고 있다. IBM의 메인 프레임의 아키텍처가 공개되지 않은 closed system 이었다. 유닉스 때와 마찬가지로 여러 곳에서 다운사이징을 진행했다. 최근 정보계는 대부분 리눅스로 전환되었으며, 계정계도 리눅스로 전환되는 추세인 것 같다.
채널계와 MCI
기존 오프라인 창구 뿐 아니라 인터넷 뱅킹이 발달하고 스마트폰 앱도 활성화되는 등, 은행 시스템에 접근하는 채널이 점점 더 다양해졌다. 이렇듯 고객이 금융 기관의 서비스를 이용하기 위해 사용하는 다양한 수단(영업점 창구, 인터넷뱅킹, ATM, 스마트폰 등)을 통틀어 채널계라고 지칭한다.
이러한 요청들이 전부 계정계에 바로 직접적으로 전달이 된다면 다양한 형태의 요청을 처리하기가 복잡해질 것이다. 이를 해결하기 위해 MCI(Multi Channel Integration)라는 통합 표준 인터페이스를 만들었다. MCI는 채널계의 다양한 채널에서 들어오는 요청을 표준화된 형식으로 통합해주는 역할을 한다.
EDMS, EAI, FEP(대외계)
EDMS 은행 시스템이 점점 복잡해짐에 따라 전자 문서를 다룰 필요성도 생기게 되었다. 문서파일의 작성부터 소멸될 때까지의 모든 과정을 관리하는 시스템을 EDMS(Electronic Document Management System), 전자문서 관리 시스템이라고 한다. 각종 전자 문서의 등록, 저장, 관리, 송수신, 조회 등을 통일된 인터페이스로 지원한다.
EAI 지금까지 살펴본 것처럼, 하나의 기업 내에도 수많은 애플리케이션이 존재한다. 그리고 이 애플리케이션들은 서로 통신을 하게 된다. 만약 모든 애플리케이션이 각각 개별적으로 연결된다면, 시스템 간 개별적인 연결이 매우 많이 생기게 된다. 시스템이 6개일 때 15개의 연결이 필요한 것이다. 이럴 경우 유지보수는 물론 통신 환경에도 많은 어려움이 발생할 수 있다. 이런 문제점을 해결하기 위해 EAI(Enterprise Architecture Integration), 전사적 애플리케이션 통합 솔루션을 적용하게 된다. 이로 인해 중앙 집중화된 시스템 관리가 가능해진다. 은행은 계정계와 정보계에 각각 EAI가 존재하여 2중으로 되어있다.
FEP FEP(Front End Processor)란 원래 메인프레임에서 통신 과부하를 경감시키기 위해 전처리 작업을 하는 과정을 의미하나, 금융권에서는 의미가 조금 와전되어 B2B 연계(대외계)를 FEP라고 부른다. (타행 이체 시 요청 전달 등) 이러한 대외계는 아무래도 최신 기술의 변화에 느리게 대응할 수밖에 없다. 이 부분이 바뀌면 모든 은행이 바뀌어야 한다는 의미이기도 하기 때문이다. 그 대표적인 예로, 통신 시 HTTP 대신 TCP를 사용해야 하고, payload를 json이 아닌 fixed string을 사용해야 한다는 점이 있다. 아주 옛날에는 fixed length라고 해서 정해진 길이로 텍스트를 잘라 전송했고, ‘;’를 기준으로 구분하는 delimiter 방식, xml, json 순서로 발전해왔다. 요즘 대부분의 인터페이스들은 json format을 제공해주지만 대외계는 아직이란 거다.
OpenAPI
원래는 FEP 하나를 설치하는 것 자체로도 돈이 많이 들었다. 그런데 Open API가 등장하며 이 문제가 해결됨과 동시에 핀테크 서비스를 확장하는 데 도움이 되었다. 오픈 API란 이용자가 일방적으로 정보를 제공받는 데 그치지 않고 직접 응용 프로그램과 서비스를 개발할 수 있도록 공개된 API를 말한다. 금융권의 오픈 API를 활용하면 고객은 금융기관의 웹/앱에 직접 접속하지 않고도 오픈 API를 이용한 서비스를 사용하여 각기 다른 금융 기관의 계좌 조회나 송금 등을 한 번에 편리하게 실행할 수 있는 것이다. 보안이 필요하다면 VPN을 넣으면 된다. 하지만 그래도 openAPI에 개인정보는 가급적 포함하지 않도록 하며, 개인 정보가 필요한 경우에는 전부 FEP로 처리하고 있다.
💡VPN이란? VPN의 목적은 크게 2가지가 있다. (1) 암호화 (2) 네트워크 가상화 이다. 여기서는 보안을 위해 사용하기 때문에 1번 역할을 하는 것이다. HTTPS는 프로토콜 자체가 암호화된 것인 데 반해, VPN은 장비가 암호화한다. 즉 원래는 VPN을 사용하기 위해서는 장비 설치가 필요하다. 하지만 최근에는 기술이 발전함에 따라 SW 서비스로도 제공된다. 다만 하드웨어에 비해 소프트웨어 VPN의 경우, 대용량 데이터가 빈번하게 들어오는 경우 속도가 많이 저하될 수 있다. 그렇기 때문에 안정성을 위해 대부분은 하드웨어 VPN을 사용한다. 하드웨어의 경우 장치가 암호화하고 것이라고 했는데, 이 말은 곧 보내는 쪽과 받는 쪽이 모두 동일한 장비를 사용해야 한다는 의미이다.
클라우드 시스템
서버 가상화 개념
IBM의 메인 프레임에는 하이퍼바이저라는 개념이 존재한다. 하이퍼바이저란 컴퓨터의 OS와 응용프로그램을 물리적 하드웨어에서 분리하는 프로세스를 말한다. 이를 통해 하나의 호스트 시스템이 여러 대의 가상 머신을 운영하여 컴퓨팅 자원을 더 효과적으로 사용할 수 있었다.
1990년대 말에 유닉스 서버의 전성기가 일어나고, 이때 서버 가상화라는 개념이 생기게 되었다고들 한다. 하지만 명확히 말하지면 서버 가상화라는 개념은 그 이전부터 존재했고, 유닉스와 함께 본격적으로 확장되었다고 볼 수 있다. IBM의 하이퍼바이저는 메인프레임이라는 특정 하드웨어에 종속된 개념이었기 때문이다.
그런데 유닉스에도 불편함은 있었다. 초기 OS가 개발된 이후로, 여러 기업이 각자의 버전으로 발전시킴에 따라 서로 호환이 잘 안된다는 점이다. 이렇듯 벤더마다 커널과 명령어 셋이 다르기 때문에 표준화된 가상화 솔루션을 만들기 어려웠다. 하지만 리눅스는 오픈 소스로 누구나 사용할 수 있었고, x86 아키텍처와 결합하면서 가상화 기술을 표준화 하기가 쉬웠다.
컴퓨터의 가상화
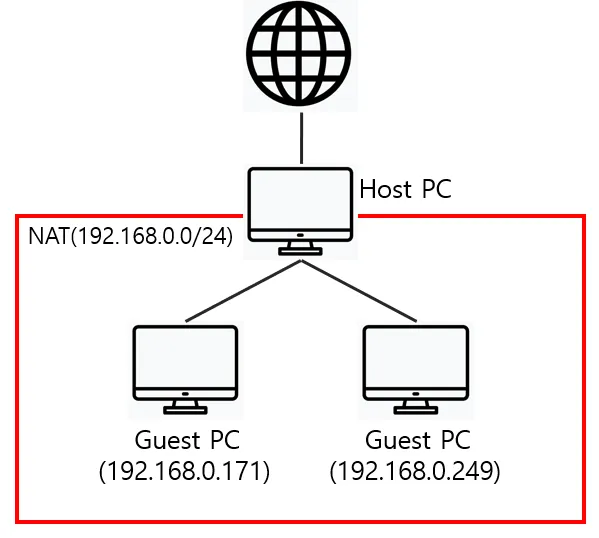
VMware의 VM은 Virtual Machine으로, 가상의 기계장치를 의미한다. 가상화 기술을 이용하여 한 개의 시스템으로 여러 개의 가상 데스크톱 환경을 구성하여 사용하는 것이다. 이러한 가상 머신에는 VirtualBox, VMware 등이 있다. VMware에는 주인(HOST)와 손님(GUEST)의 개념이 있다. 하나의 컴퓨터(host) 안에 여러 개의 가상 머신(guest)를 만드는 것으로 이해하면 된다. 이 host를 나눌 때 하이퍼바이저를 사용한다.
이러한 VM의 개념이 발전하여 SDC(Soft Defined Compute)가 등장했다. SDC는 소프트웨어 기반으로 컴퓨팅 리소스를 동적으로 관리하고 최적화하는 개념이다. VM은 하드웨어 중심적인 환경인 데 반해서, SDC는 소프트웨어를 통해 CPU, 메모리 등의 자원을 유연하게 관리할 수 있다. SDC + SDN(Soft Defined Network) + SDS(Soft Defined Storage) 3가지 개념을 합치면 결국 클라우드가 된다. 클라우드가 등장하면서 컴퓨팅 환경과 트렌드는 완전히 변화했다. 이렇게 좋은 클라우드 기술, 당연히 은행도 사용할까? 물론 사용하지만 VM도 여전히 사용 중이다.
은행은 왜 계속 VM을 쓸까?
이를 이해하기 위해서는 VM 과 컨테이너에 대한 비교가 필요하다. 우선 둘 모두 host OS 위에서 돌아간다. VM의 경우 하이퍼바이저를 사용하여 여러 Guest OS를 올려 여러 VM을 모두 별도의 OS를 가지고 있는 것처럼 사용 가능하다. 컨테이너의 경우 도커 등을 활용해서 여러 컨테이너들 간에 호스트 자원을 분리해서 사용할 수 있게 해준다. 이는 리눅스의 고유 기술인 namespace와 cgroup을 이용한 것이다.
은행이 컨테이너를 사용하지 않고 아직까지 VM을 사용하는 이유는 결국 보안성 때문이라고 생각한다. 컨테이너는 관리가 편하지만, 구조적으로 하나의 OS 커널을 공유하기 때문에 문제가 생겼을 때 다른 서비스에도 영향이 미칠 수 있다. 반면 VM은 서로 독립된 OS 환경을 제공하기 때문에 하나의 VM이 공격 당하더라도 각 VM은 독립적이기 때문에 다른 시스템에 피해가 가지 않는다.
OpenStack 플랫폼
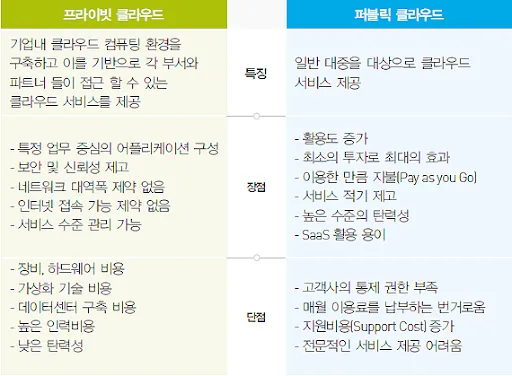
다시 돌아와서, 클라우드 기술은 다양한 산업과 서비스에서 활발하게 사용되고 있다. AWS, Azure, GCP와 같은 서비스들이 대표적이다. 그런데 보안을 중요시하는 금융권에서 타사의 클라우드 서비스를 쓴다? 자신들만의 리소스를 활용해서 새로운 클라우드 서비스를 만들고 싶지 않을까? 이것이 프라이빗 클라우드이다.
그리고 프라이빗 클라우드 구축 시에 사용하는 것이 OpenStack이다. OpenStack은 퍼블릭/프라이빗 클라우드를 구축/관리하는 오픈소스 플랫폼이다. 하나금융의 하나클라우디아가 이를 기반으로 개발되었다.
Docker와 K8s
기존 VMware는 물리 서버(host) 하나를 하이퍼바이저를 이용해서 여러 개의 가상 머신으로 나누는 방식으로 동작했다. 이러한 방식은 무거운 구조를 가진다는 단점이 있었고, 이후에 나온 것이 컨테이너 기술이다. 대표적으로 Docker와 이를 관리하는 K8s(쿠버네티스)가 있다. 컨테이너는 VM과 다르게 host의 OS 커널을 공유하면서 프로세스 수준의 격리를 제공한다. 이는 VMware보다 훨씬 가볍고 빠르게 애플리케이션을 실행할 수 있도록 도와줬다. 이러한 컨테이너가 많아짐에 따라 이를 한 번에 관리/배포/확장/모니터링하기 위한 도구의 필요성이 등장했다. 처음에는 Docker swarm 등 다양한 툴이 있었지만, 현재로서는 사실상 쿠버네티스가 표준이 되었다고 볼 수 있다.
쿠버네티스는 오픈소스로 공개되었기 때문에 여러 기업에서 이를 기반으로 상용 제품을 만들었다. RedHat의 Open Shift는 여기에 기업용 기능(보안, 인증 등)이 추가된 것이다. OpenShift의 오픈소스 버전으로 OKD(Origin Community Distribution)도 있다.
IaC(Infrastructure as Code)
쿠버네티스는 애플리케이션이 실행되는 환경이 온프레미스든, 프라이빗 클라우드든, 퍼블릭 클라우드든 상관없이 동일한 실행 환경을 제공해준다. YAML 파일을 통해 필요한 리소스를 정의하며, 이 파일을 쿠버네티스 클러스터에 적용하면 완전히 동일한 상태를 언제 어디서든 재현할 수 있다. 이것이 바로 코드로 인프라를 관리하는 IaC의 예이다.
그보다 더 하위 레벨의 인프라(VM, 네트워크, LB 등)을 코드로 관리할 수 있도록 도와주는 도구가 바로 HashiCorp의 Terraform이다. 쿠버네티스와 테라폼 모두 코드로 인프라를 정의한다는 공통점이 있지만, 쿠버네티스는 컨테이너 오케스트레이션만 다루고 테라폼은 클라우드 자원의 생성/제어를 다룬다는 점에서 차이가 있다. Terraform은 원래 오픈소스로 시작했지만, 최근에는 라이센스 변경으로 인해 커뮤니티 주도로 OpenTofu가 오픈소스로 제공되고 있다.
여기에 Ansible을 같이 사용한다면 완전한 자동화를 만들 수 있다. Ansible이란 Python으로 개발된 오픈소스 IaC 솔루션으로, 시스템을 구성하고 애플리케이션을 배포하는 등의 IT 작업을 자동화할 수 있다. httpd를 설치하고, 방화벽을 설정하고, 패키지를 설치하고.. 등의 과정을 모두 하나의 Playbook 파일로 작성하는 것이다. 그렇다면 ansible과 쉘 스크립트의 차이점은 무엇일까? 가장 큰 차이는 멱등성인 것 같다. 멱등성이란 “어떤 연산이 여러 번 수행되더라도 결과가 달라지지 않는 성질”을 뜻하며, 쉘의 경우 같은 모듈을 반복 실행했을 때 중복 생성이나 충돌 등의 발생 가능성이 있다.
타 관계사에 솔루션을 설치할 때, 전부 내부망이기 때문에 기본적으로 설치 파일을 보안 USB에 담아 가져가고 있다. 그 과정에서 USB 마운트라는 용어를 접하게 되었고, 파일 시스템의 종류에 따라 라이브러리가 추가로 필요한 경우도 있었다. 이를 이해하기 위해서 관련 개념들을 간단히 정리해보았다.
USB 마운트
USB 마운트란?
USB를 운영체제의 파일 시스템에 연결하여 사용할 수 있도록 하는 과정을 의미한다.
마운트 시 일반적인 디렉터리처럼 USB 내부의 파일을 읽고 쓰고 수정할 수 있다.
마운트 과정
fdisk -l
cd /home
mkdir usb # 없다면 생성 필요
mount [디바이스 경로] [디렉토리 경로]
# ex: mount /dev/sda1 /home/usb
umount [디바이스 경로]
fdisk는 현재 시스템에 연결된 디스크와 파티션 정보를 출력하는 명령어로, USB가 정상적으로 인식되었는지 확인하기 위해 실행한다.
디바이스 경로는 usb 장치가 인식된 경로이고, 디렉토리 경로는 앞선 폴더의 데이터를 마운트할 대상 위치이다. 해당 디렉토리가 없다면 mkdir로 생성이 필요하다. 즉, 위 명령어 수행 시 USB에 저장된 파일을 ./usb 폴더 내에서 접근 가능하다.
umount는 unmount의 약자로, 장치를 제거하기 전에 꼭 실행해줘야 하는 작업이다. 이를 생략할 경우 데이터 손실이 발생할 수 있다.
파일 시스템
USB는 다양한 형식의 파일을 지원한다. 파일 시스템이란 운영체제가 데이터를 저장하고 관리하는 방식을 의미하며, USB, SSD 등 모든 저장 장치는 특정한 파일 시스템을 사용해야 데이터를 읽고 쓸 수 있다. 그러면 하나의 저장 장치에는 한 종류의 파일밖에 담지 못할까? USB를 여러 파티션으로 나누면 각 파티션에 다른 파일 시스템을 적용할 수 있다. 파일 시스템의 종류는 다양하지만, 현재 내가 접한 종류는 다음과 같다.
NTFS
Windows에서 기본적으로 사용하는 파일 시스템
리눅스에서도 마운트 가능하지만, NTFS 전용 드라이버(ntfs-3g) 설치 필요
파일 크기 제한이 거의 없다
exFAT(Extended File Allocation Table)
마이크로소프트에서 개발한 파일 시스템으로, NTFS보다 가볍게 설계된 파일 시스템
파일 크기 제한(4G)와 파티션 크기 제한(2TB)가 없는 FAT 계열 파일 시스템임
Windows, macOS, Linux 모두에서 호환 가능하여 대용량 USB나 SD카드에서 많이 사용
오늘 오후 2~5시에 진행됐던 쇼미더코드가 끝났다. 결론은 세 문제 다 풀긴 풀었다! 와아아 👏 A는 부분합 문제, B는 BFS 문제, C는 dp 문제였다. 공개된 문제를 보니 난이도는 골드5, 5, 3이었다. 직접 풀어보고 싶으신 분들은 이쪽 → https://www.acmicpc.net/category/detail/3451
사실 A번부터 풀기 시작했는데 처음에 잘 안풀리길래 그냥 관둘까 하다가 B번이 너무 쉬워보여서 조금만 더 해보자 했다. 다행히 B번은 1트만에 풀었는데 그게 이미 대회가 시작된지 1시간 30분이 지난 뒤여서 좀 아쉬웠다. C번은 처음에 문제를 이해하는 데 시간이 좀 걸렸고, 전체 틀을 금방 잡았는데 사소하게 놓친 부분들이 있어 이것저것 고치다보니 제출횟수가 좀 많아졌다. C번까지 풀고 나니 20분정도가 남았고, A번을 다시 보는데 갑자기 그제서야 방법이 확 생각나서.. 후다닥 풀고 종료 5분 전에 다 제출했다. 아래 코드는 급하게 푼 만큼, 가독성이나 효율성이 안좋을 수 있는 점 참고 바란다.
+
1월 30일에 테스트 결과가 이메일로 발송됐다. 제출 횟수나 시간 등을 봤을 때 금손은 절대 아닐거라 생각하고 있었고, 예상대로 은손을 받았다.
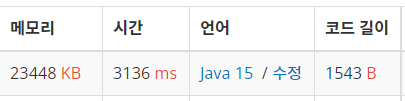
A번: 신을 모시는 사당
입력된 1의 개수, 2의 개수를 카운팅해서 배열에 넣도록 했다. 1은 음수, 2는 양수로 해서 가장 큰/작은 연속된 수열의 합을 구하는 로직을 적용했다.
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.StringTokenizer;
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int n = Integer.parseInt(br.readLine());
ArrayList<Integer> arr = new ArrayList<>();
int sum = 0;
StringTokenizer st = new StringTokenizer(br.readLine());
for (int i = 0; i < n; i++) {
int val = Integer.parseInt(st.nextToken());
if(val == 1){
if(sum < 0) sum--;
else{
arr.add(sum);
sum = -1;
}
}
else{
if(sum > 0) sum++;
else{
arr.add(sum);
sum = 1;
}
}
}
arr.add(sum);
int arrSize = arr.size();
int largeSum = 0, smallSum = 0;
int largest = 0, smallest = 0;
for (int i = 0; i < arrSize; i++) {
for (int j = i; j < arrSize; j++) {
largeSum += arr.get(j);
smallSum += arr.get(j);
largest = Math.max(largest, largeSum);
smallest = Math.min(smallest, smallSum);
}
largeSum = smallSum = 0;
}
int answer = Math.max(largest, -smallest);
System.out.println(answer);
}
}
B번: 도넛 행성
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.LinkedList;
import java.util.Queue;
import java.util.StringTokenizer;
public class Main {
static class Pos{
int x, y;
Pos(int x, int y){
this.x = x;
this.y = y;
}
}
static int N, M;
static int[] dx = {-1, 0, 1, 0};
static int[] dy = {0, 1, 0, -1};
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = null;
st = new StringTokenizer(br.readLine());
N = Integer.parseInt(st.nextToken());
M = Integer.parseInt(st.nextToken());
int[][] star = new int[N][M];
boolean[][] visited = new boolean[N][M];
for(int i = 0;i < N;i++){
st = new StringTokenizer(br.readLine());
for(int j = 0;j < M;j++){
star[i][j] = Integer.parseInt(st.nextToken());
if(star[i][j] == 1) visited[i][j] = true;
}
}
int answer = 0;
for(int i = 0;i < N;i++) {
for (int j = 0; j < M; j++) {
if(visited[i][j]) continue;
bfs(i, j, visited);
answer++;
}
}
System.out.println(answer);
}
private static void bfs(int i, int j, boolean[][] visited) {
Queue<Pos> q = new LinkedList();
q.add(new Pos(i, j));
while(!q.isEmpty()){
Pos cur = q.poll();
if(visited[cur.x][cur.y]) continue;
visited[cur.x][cur.y] = true;
for(int d = 0;d < 4;d++){
int nx = cur.x + dx[d];
int ny = cur.y + dy[d];
// set bound
if(nx >= N) nx -= N;
else if(nx < 0) nx += N;
if(ny >= M) ny -= M;
else if(ny < 0) ny += M;
if(!visited[nx][ny])
q.add(new Pos(nx, ny));
}
}
}
}
C번: 미팅
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.StringTokenizer;
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = null;
st = new StringTokenizer(br.readLine());
int N = Integer.parseInt(st.nextToken());
int M = Integer.parseInt(st.nextToken());
int C = Integer.parseInt(st.nextToken());
int[][] W = new int[C+1][C+1];
int[] aChar = new int[N];
int[] bChar = new int[M];
// 성격 간의 만족도 저장
for (int i = 1; i <= C; i++) {
st = new StringTokenizer(br.readLine());
for (int j = 1; j <= C; j++) {
W[i][j] = Integer.parseInt(st.nextToken());
}
}
// A와 B 학생들의 성격 저장
st = new StringTokenizer(br.readLine());
for (int i = 0; i < N; i++)
aChar[i] = Integer.parseInt(st.nextToken());
st = new StringTokenizer(br.readLine());
for (int i = 0; i < M; i++)
bChar[i] = Integer.parseInt(st.nextToken());
// dp 초기값 설정
long[][] dp = new long[N][M];
long answer = 0;
dp[0][0] = W[aChar[0]][bChar[0]];
for (int i = 1; i < N; i++)
dp[i][0] = Math.max(dp[i-1][0], W[aChar[i]][bChar[0]]);
for (int i = 1; i < M; i++)
dp[0][i] = Math.max(dp[0][i-1], W[aChar[0]][bChar[i]]);
// 최대 만족도 계산
for (int i = 1; i < N; i++) {
for (int j = 1; j < M; j++) {
// 악수를 하는 경우와 안하는 경우 고려
long val = Math.max(dp[i-1][j], dp[i][j-1]);
dp[i][j] = Math.max(val, dp[i-1][j-1] + W[aChar[i]][bChar[j]]);
}
}
System.out.println(dp[N-1][M-1]);
}
}